10. Diagnostic tests
Performance of a binary classification test
Diagnostic tests are used to classify individuals into groups – in particular they are used in medicine. The decision of the doctor in regard to diagnosis and therapy is based on the variables characterizing the patient. It is therefore essential for the doctor: a) to know which variables hold the most information and b) to be able to interpret the information in the best possible way.
How this is done depends on the type of the variable and on the type of decision, which has to be made. Some descriptive variables are by nature dichotomous or binary like variceal bleeding being either present or absent. However, many variables like liver function tests and the hepatic venous pressure gradient (HVPG) are measured on a continuous scale, i.e. they are quantitative variables.
However, a doctor’s decision has to be binary, i.e. yes or no concerning a specific diagnosis and treatment. Therefore, for a simple diagnostic test to provide a yes or no answer, quantitative variables need to be made binary by introducing a threshold or cut-off level to distinguish between ‘normal’ and ‘abnormal’ values.
The efficiency pf diagnostic tests can be assessed by their sensitivity, specificity, positive and negative predictive values, likelihood ratios, and ROC curves. In the following, these methods will be illustrated by an important variable in hepatology, namely the hepatic venous pressure gradient (HVPG).
CLASSIFICATION OF ‘NORMAL ‘ AND ‘ABNORMAL’
 Most diagnostic tests would not be able to distinguish completely between ‘normal’ and ‘abnormal’; usually, some overlap of varying degrees would be present between the two categories.
Most diagnostic tests would not be able to distinguish completely between ‘normal’ and ‘abnormal’; usually, some overlap of varying degrees would be present between the two categories.
The overlap causes some patients to be misclassified. The larger the overlap, the poorer the discrimination of the test and the larger the proportion of misclassified patients.
This is illustrated in figure 1. Patients with the condition in question (here variceal bleeding) could have a positive test (here hepatic venous pressure gradient (HVPG) above 12 mm Hg). They would be the True Positives (TP).
But some patients with the condition could have a negative test i.e. an HPVG below 12 mm Hg. They would be the False Negatives (FN).
In patients without the condition, the test would frequently be negative i.e. the HVPG would be below 12 mm Hg. That would the True Negatives (TN).
But some patients without the condition could have a positive test i.e.an HVPG above 12 Hg. That would be the False Positives (FP).
The false negatives and the false positives are the patients who are misclassified. An effective diagnostic test would only misclassify few patients. The classification of the patients by the test can be summarized in a 2 × 2 table as shown in the upper left part of table 1.

SENSITIVITY AND SPECIFICITY
The performance of a binary classification test can be summarized as sensitivity and specificity.
The sensitivity measures the proportion of actual positives, which are correctly identified as such. It is also called the true positive rate. In the example, in table 1 the sensitivity or true positive rate is the probability of high HVPG in patients with bleeding.
The specificity measures the proportion of actual negatives, which are correctly identified as such. It is also called the true negative rate. In the example, the specificity or true negative rate is the probability of low HVPG in patients with no bleeding.
A sensitivity (true positive rate) of 100% means that the test classifies all patients with the condition correctly. A negative test result can thus rule out the condition. A specificity (true negative rate) of 100% means that the test classifies all patients without the condition correctly. A positive test result can thus confirm the condition.
Complementary to the sensitivity is the false negative rate, i.e. it is equal to 1 – sensitivity. This is sometimes also called the type 2 error (β), which is the risk of overlooking a positive finding when it is in fact true. In the example used the false negative rate is the probability of bleeding in patients with low HVPG.
Complementary to the specificity is the false positive rate, i.e. it is equal to 1 – specificity. This is sometimes also termed the type 1 error (α), which is the risk of a positive finding when it is in fact false. In the example, the false positive rate is the probability of no bleeding in patients with high HVPG.
POSITIVE AND NEGATIVE PREDICTIVE VALUES
The weaknesses of sensitivity and specificity are a) that they do not take the prevalence of the condition into consideration and b) that they just give the probabilities of test outcomes in patients with or without the condition.
The doctor needs the opposite information, namely the probabilities of the condition in patients with a positive or negative test outcome, i.e. the positive predictive value and negative predictive values defined below (Table 1).
The positive predictive value (PPV) is the proportion of patients with positive test results who are correctly diagnosed as having the condition. It is also called the post-test probability of the condition In the example the positive predictive value (PPV) is the probability of bleeding in patients with high HVPG..
The negative predictive value (NPV) is the proportion of patients with negative test results who are correctly diagnosed as not having the condition. In the example, the negative predictive value (NPV) is the probability of no bleeding in patients with low HVPG.
Both the positive and negative predictive values depend on the prevalence of the condition with may vary from place to place. With decreasing prevalence of the condition, the positive predictive value (PPV) decreases and the negative predictive value (NPV) increases – conversely with an increasing prevalence of the condition.
LIKELIHOOD RATIO
A newer tool for expressing the strength of a diagnostic test is the likelihood ratio, which incorporates both the sensitivity and specificity of the test and provides a direct estimate of how much a test result will change the odds of having the condition.
The likelihood ratio for a positive result (LR+) tells you how much the odds of the condition increase when the test is positive.
The likelihood ratio for a negative result (LR-) tells you how much the odds of the condition decrease when the test is negative.
Table 1 shows how the likelihood ratios are being calculated using our example.
The positive likelihood ratio (LR+) is the ratio between the true positive rate and the false positive rate. In our example, it is the probability of high HVPG among bleeders divided by the probability of high HVPG among non-bleeders.
The negative likelihood ratio (LR-) is the ratio between the false negative rate and the true negative rate. In the example, it is the probability of low HVPG among bleeders divided by the probability of low HVPG among non-bleeders.
The advantages of likelihood ratios are:
- That they do not vary in different populations or settings because they are based on the ratio of rates.
- They can be used directly at the individual level.
- They allow the clinician to quantitate the probability of bleeding for any individual patient.
- Their interpretation is intuitive: i.e. the larger the LR+, the greater the likelihood of bleeding, the smaller the LR-, the lesser the likelihood of bleeding.
Likelihood ratios can be used to calculate the post-test probability of the condition using Bayes’ theorem, which states that the post-test odds equals the pre-test odds times the likelihood ratio: Post-test odds = pre-test odds × likelihood ratio.
Using our example (Table 1) we can now calculate the probability of bleeding with high HVPG using LR+ as follows:
The pre-test probability p1, (or prevalence) of bleeding is 0.25. The pre-test probability p2 (or prevalence) of no bleeding is thus 1 – 0.25 = 0.75. The pre-test odds of bleeding/no bleeding = p1 / p2 = 0.25 / 0.75 = 0.34. Since LR+ = 6.9 we can (using Bayes’ theorem) calculate the post-test odds o1 as 0.34 × 6.9 = 2.34.
Then we can calculate the post-test probability of bleeding with a high HVPG as o1 / (1 + o1) = 2.34 / 3.34 = 0.70. Note that this is the same value as the PPV.
Similarly, we can calculate the probability of bleeding with a low HVPG using LR- as follows: As before the pre-test odds of bleeding/no bleeding is 0.34. Since the LR- = 0.09 the post-test odds o2 = 0.34 × 0.09 = 0.03. Then the post-test probability of bleeding with a low HVPG is o2 / (1 + o2) = 0.03 / 1.03 = 0.03. Note that this is the same value as 1 – NPV.
THE ROLE OF THE DISCRIMINATION THRESHOLD
 The specification of the discrimination threshold or cut-off is important for the optimal performance of a diagnostic test based on a quantitative variable test like the HVPG.
The specification of the discrimination threshold or cut-off is important for the optimal performance of a diagnostic test based on a quantitative variable test like the HVPG.
As the position of the threshold changes, the sensitivity and the specificity also change. If you want a high sensitivity (true positive rate), you would specify a relatively low discrimination threshold. If you want a high sensitivity (true negative rate) you would specify a relatively high discrimination threshold.
The effect of changing the position of the discrimination threshold is illustrated in figure 2 (left side) together with the receiver operating characteristic (ROC) curve (Figure 2, right side), which summarizes the overall performance of a diagnostic test.
The ROC curve shows the true positive rate (sensitivity) as a function of the false positive rate (1 – specificity) as the discrimination threshold runs through all the possible values.
SEPARATION BETWEEN POSITIVE AND NEGATIVE TEST VALUES
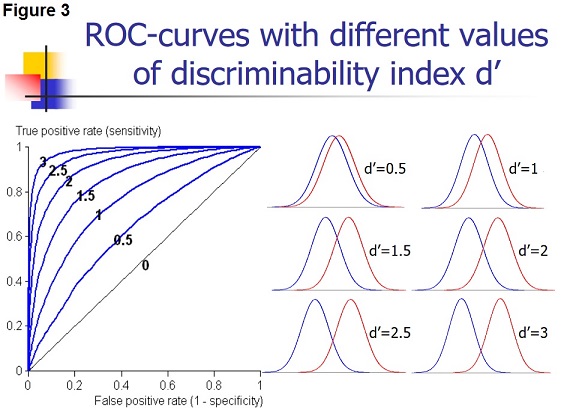
The degree of separation between two distributions is given by the discriminability index d’, which is the difference in means of the two distributions divided by their standard deviation.
Figure 3 shows that with increasing separation (decreased overlap) between the distributions the discriminability index increases (Figure 3, right side), and the middle of the ROC curve moves up toward the upper left corner of the graph (Figure 3, left side).
For the discriminability index to be valid, the distributions need to be normal with similar standard deviations. In practice, these requirements may not always be fulfilled.
The area under the ROC curve (AUC) or c-statistic is another measure of how well a diagnostic test performs (Figure 4).  With increasing discrimination between the test distributions for patients with and without the condition, the AUC or c-statistic will increase.
With increasing discrimination between the test distributions for patients with and without the condition, the AUC or c-statistic will increase.
An AUC of 0.5 means no discrimination, and an AUC = 1 means perfect discrimination. Most frequently the AUC or c-statistic would lie in the interval 0.7-0.8.
The standard error of an AUC can be calculated and ROC curves for different diagnostic tests derived from the same patients can be compared statistically. In this way, the test with the highest diagnostic accuracy in the patients can be found.
The ROC curve can also be used to define the optimal cut-off value for a test by localizing the value where the overall misclassification (false positive rate plus false negative rate) is minimum. This will usually be the cut-off value corresponding to the point of the ROC curve, which is closest to the upper left corner of the plot (i.e. point [0, 1]).
The performance of diagnostic tests may be improved if ‘noise’ in the measurement of the diagnostic variable e.g. HVPG can be reduced as much as possible. Therefore every effort should be made to reduce the influence of factors, which could make the measurements less accurate. Thus if ‘noise’ can be reduced, the spread of the test distributions would be less, the test distributions would be narrower with less overlap, and this would improve the test’s discrimination between those with and those without the condition.
 WEAKNESSES OF DICHOTOMIZATION
WEAKNESSES OF DICHOTOMIZATION
The preceding methods of utilizing the information provided by a quantitative diagnostic variable like HVPG involve dichotomization defining ‘normal’ and ‘abnormal’.
Thus the quantitative information provided by the test value within each of the two defined groups (normal or abnormal) is not utilized. All test values smaller than the cutoff are considered equal and all test values larger than the cutoff are also considered equal.
By disregarding the actual value of the test variable within each of the groups (normal, abnormal) information is lost.
STRENGTH OF EVIDENCE BASED ON TEST-VALUE
In the following, a method utilizing quantitative test-values as such without dichotomization will be described.
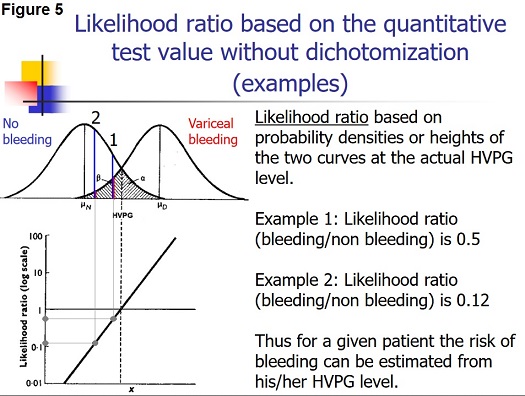
Considering the HVPG there would be a relation between the risk of bleeding and the actual level of HVPG irrespective of any defined threshold: the smaller the HVPG, the lesser the risk of bleeding; the larger the HVPG, the greater the risk of bleeding.
The risk can be expressed as the likelihood ratio (the ratio between the probability densities or heights) of the two distribution curves at the actual HVPG level (Figure 5). From the likelihood ratio and the pre-test probability of bleeding the post-test probability of bleeding can be estimated using Bayes’ theorem as shown previously in this paper.
However, this likelihood ratio method would only be valid if the distribution curves for bleeding and non-bleeding were normal with the same standard deviation. These requirements may not be entirely fulfilled in practice. If they are not fulfilled it may be possible to perform a normalizing transformation of the variable or to perform analysis after dividing the information of the quantitative variable into a smaller number of groups e.g. 3 or 4 groups.
UTILIZING THE COMBINED INFORMATION OF MORE VARIABLES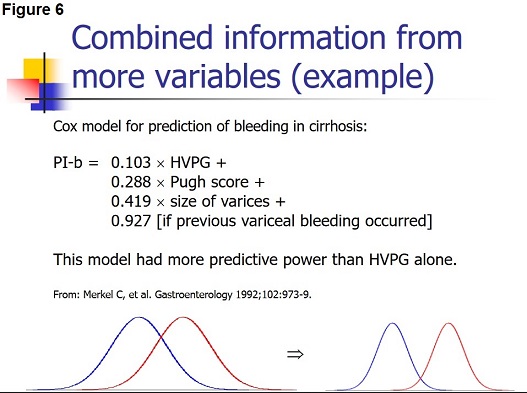
Besides the key variable HVPG, other descriptive variables (e.g. symptoms, signs, and liver function tests) may influence the risk of bleeding from varices. By utilizing such additional information, estimation of the risk of bleeding in a given patient may be improved.
Such predictive models may be developed using multivariate statistical analysis like logistic regression or Cox regression analysis. In the literature, there are many examples of utilizing the combined diagnostic information of more variables.
Here will just be mentioned one example by Merkel, et aI. (Figure 6) who showed that the prediction of variceal bleeding could be improved by supplementing the information provided by HVPG with information on the Pugh score, the size of the esophageal varices, and whether variceal bleeding had occurred previously. Their multivariate model had significantly more predictive power than HVPG alone.
CONCLUSION
The methods for the evaluation of simple diagnostic tests are important tools for the optimal evaluation of patients. They may, however, have limitations for quantitative variables, since the dichotomization, which needs to be made, has the consequence that quantitative information is being lost. Quantitative variables should be kept as such whenever possible.
Prediction of diagnosis and outcome may be markedly improved if more informative variables can be combined using multivariate statistical analysis e.g. logistic regression analysis. Preferably dichotomization of quantitative variables should only be used in the last step when a binary decision (i.e. yes/no in regard to diagnosis or therapy) has to be made.
Powerpoint Presentation and Paper
Here you can see the slides of a PowerPoint presentation on the Methodology of Diagnostic Tests that I did at the EASL (European Association for the Study of the Liver) Monothematic Conference on “Portal hypertension: advances in knowledge, evaluation, and management” in Budapest in 2009.
Here is the paper on the Methodology of Diagnostic Tests that I published in Annals of Hepatology as a sequel to the above lecture.
Calculation online
Using this link you can calculate the sensitivity, specificity, predictive values, and likelihood ratios with 95% confidence limits.
Using this link you can calculate the receiver operating characteristic (ROC) curve for a set of data. The first data column should define the category to which the individual belongs – scored as 0 or 1. The second data column should hold the variable value for the individual. The data format type 5 is the most general format and should be used in most cases.
Here is another fine link to Calculate test Sensitivity and Specificity and ROC curves. This link provides many additional details of the calculation. The “Stacked version” is the probably most convenient. Here the first column should contain status identifiers as either “Infected” or “Uninfected” and the second column should contain the corresponding test result.